
简述:
在计算广告系统中,一个可以携带广告请求的用户流量到达后台时,系统需要在较短时间(一般要求不超过100ms)内返回一个或多个排序好的广告列表。在广告系统中,一般最后一步的排序
score=bid*pctralpha。其中alpha参数控制排序倾向,如果alpha<1,则倾向于pctr(预测点击率),否则倾向于bid。在推荐系统中,也有类似的需求,当用户请求到达后台的时候,我们需要返回一个排序好的推荐列表。早期的推荐系统主要以协同过滤和基于内容的推荐为主,近年来推荐系统的主流形式也变成和广告类似的两步走模式:先召回一个候选队列,然后排序;在排序这一步有很多种不同的策略,比如pair-wise的一些分类算法之类,但更多还是类似Youtube之类的计算一个分数,然后排序;这个分数里往往也少不了item的pctr这个关键因子。
综上所述,在计算广告、推荐系统等不同业务系统中都对预测项目的点击率有需求,所以很多研究都集中在此,本文将分析这些算法的优缺点。
几种常用点击率模型介绍
LR
- LR的优点很明确,就是算法简单,易并行和工程化。sigmoid函数的取值范围是0-1,刚好可以解释为点击概率,而输入的范围却可以很宽广,能够处理超高纬度稀疏问题。
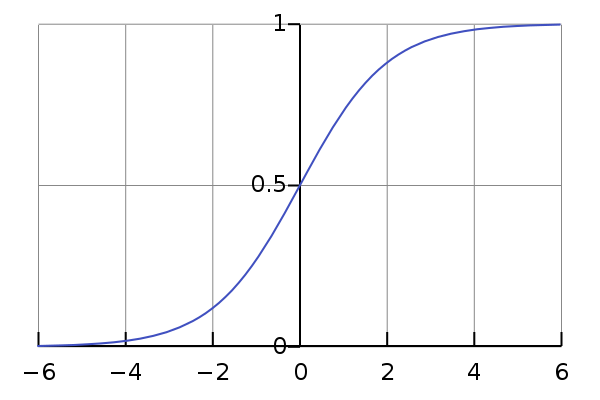
- 但是LR也存在缺点。LR不能很好处理连续型特征,也无法对特征进行组合,因此会带来大量特征工程方面的工作。还有就是LR的训练算法,其中sgd是一种非常通用的优化算法,但实际业务中往往不是最佳选择。原因是因为当函数的取值已经接近于1或0时,函数的梯度方向接近于平行,此时sgd的收敛速度越来越慢。
GBDT+LR
- 该算法是Facebook在2014年发表,是ctr领域里面非常经典的算法。前面提到LR的特征组合问题,实际业务当遇到特征爆炸问题和维度灾难问题时,LR算法可能就会遇到瓶颈。该算法提出了一种解决特征组合问题的方案,基本思路就是利用树模型的组合特性来自动做特征组合,弥补了lr的不足。整体架构如下:
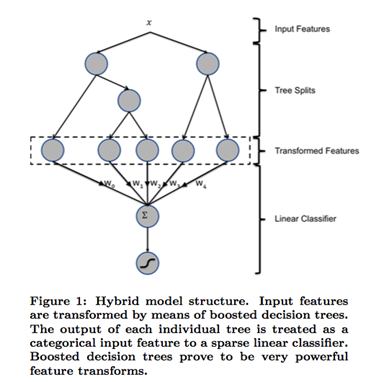
- 缺点就是很容易过拟合,需要根据业务场景注意在树的棵数和深度上做一定的裁剪,才能平衡精度和过拟合。
FTRL
- 有实验证明,L1-FOBOS这一类基于梯度下降的方法有较高的精度,但是L1-RDA却能在损失一定精度的情况下产生更好的稀疏性。FTRL可以视作RDA和FOBOS的结合,同时具备二者的优点。
FM
fm是一种可以自有设置特征组合度数的回归算法。
Fm的优势是因为可以自动进行特征间的组合,这解决了两个问题,一个是系数数据因为特征组合而能得到不错的 backgroud model 效果;另一个是特征组合解决了人工组合的尴尬,GBDT+LR 与此有异曲同工之妙,因此 FM 常常和 GBDT+LR 来一起讨论;从应用范围来看,业界 GBDT+LR 的使用范围应该是比 FM 要广的;国内我所知只有世纪佳缘 [7]是使用 FM 替代了 GBDT+LR。
FM的另一个优点是会算出每个 feature 对应的向量 v;这个向量可以看做对 feature 的一种 embeding,例如后面 WDL 的场景,或者是 GBDT+LR 里对 categorical feature 做 embeding,后者我们正在计划尝试;前者因为可以通过 joint learning 直接学习最佳的 embedding 向量,所以一般不会单独使用 fm 来对 feature 做 embeding。
FM的不足之处是在 dense 数据集情况下,反而可能表现不佳,鱼与熊掌不可兼得啊!
WDL
- 首先是对 categorical feature 进行 embeding,然后和 continous feature 一起 concatenate 成一个向量,通过三层 relu 网络来做特征的表示学习;另一方面对于 categorical feature 还可以进行人工交叉组合,与左边网络自己学习到的特征一起加入到顶层 lr 模型里作为最终的特征。
- WDL 的缺陷主要体现在两方面,一方面是在线 predict 时的性能瓶颈决定不能使用太宽、太深的网络,另一方面是如果做 online learning