通常,协同过滤算法按照数据使用,可以分为:
- 基于用户(UserCF)—基于用户相似性
基于用户的协同过滤,通过不同用户对物品的评分来评测用户之间的相似性,基于用户之间的相似性做出推荐。简单来讲,就是给用户推荐和他兴趣相似的其他用户喜欢的物品。
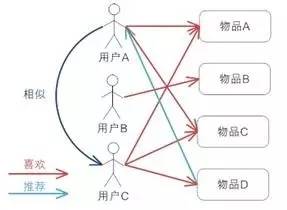
上图示意出基于用户的协同过滤推荐机制的基本原理,假设用户 A 喜欢物品 A,物品 C,用户 B 喜欢物品 B,用户 C 喜欢物品 A ,物品 C 和物品 D;从这些用户的历史喜好信息中,我们可以发现用户 A 和用户 C 的口味和偏好是比较类似的,同时用户 C 还喜欢物品 D,那么我们可以推断用户 A 可能也喜欢物品 D,因此可以将物品 D 推荐给用户 A。
- 基于项目(ItemCF)—基于商品相似性
基于项目的协同过滤,通过用户对不同item的评分来评测item之间的相似性,基于item之间的相似性做出推荐。简单来将,就是给用户推荐和他之前喜欢的物品相似的物品。
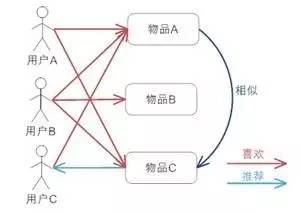
上图示意出基于项目的协同过滤推荐机制的基本原理, 假设用户 A 喜欢物品 A 和物品 C,用户 B 喜欢物品 A,物品 B 和物品 C,用户 C 喜欢物品 A,从这些用户的历史喜好可以分析出物品 A 和物品 C 时比较类似的,喜欢物品 A 的人都喜欢物品 C,基于这个数据可以推断用户 C 很有可能也喜欢物品 C,所以系统会将物品 C 推荐给用户 C。
- 基于模型(ModelCF)
基于模型的协同过滤推荐就是基于样本的用户喜好信息,训练一个推荐模型,然后根据实时的用户喜好的信息进行预测,计算推荐。
基于模型的方法不像基于邻域的方法,使用用户项评分直接预测新的项。基于模型的方法会在使用评分去学习预测模型的基础上,去预测新项。一般的想法是使用机器学习算法建立用户和项的相互作用模型,从而找出数据中的模式。在一般情况下,基于模型的CF被认为是建立CF推荐系统的更先进的算法。有许多不同的算法可用于构建模型并基于这些模型进行预测,例如,贝叶斯网络、聚类、分类、回归、矩阵分解、受限玻尔兹曼机等等。这些技术在为了最终赢得Netflix奖的解决方案中扮演了关键角色。Netflix发起了一个竞赛,从2006年到2009年提供一百万美元奖金,颁发给产生的推荐比他们自己的推荐系统精确10%以上的推荐系统团队。成功获奖的解决方案是Netflix研发的一个集成(即混合)了超过100种算法模型,这些算法模型都采用了矩阵分解和受限玻尔兹曼机
Spark MLlib当前支持基于模型的协同过滤,其中用户和商品通过一小组隐性因子进行表达,并且这些因子也用于预测缺失的元素。MLlib使用交替最小二乘法(ALS)来学习这些隐性因子。
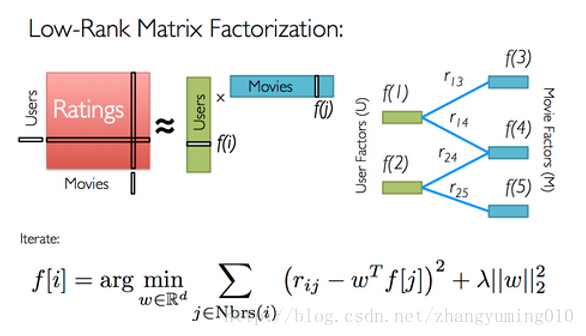
这种ALS算法不像基于用户或者基于物品的协同过滤算法一样,通过计算相似度来进行评分预测和推荐,而是通过矩阵分解的方法来进行预测用户对电影的评分。即如下图所示。