
本篇文章介绍如何使用python(requests+BeautifulSoup)的方法对页面进行抓取和数据提取。通过使用requests库对链家网二手房列表页进行抓取,通过BeautifulSoup对页面进行解析,并从中获取房源价格,面积,户型和关注度的数据。
准备工作
- 为了方便数据库建表读写,我们使用python ORM工具Peewee。并且使用BeautifulSoup+Requests对页面进行抓取和数据提取。具体所需依赖包如下
1 | appdirs==1.4.3 |
- 该工具使用python对链家网页面进行数据抓取,然后存到数据库中,目前支持三种数据库类型(MYSQL,Postgres,SQLite)。由于我们是中文存储,所以在配置数据库时注意设置UTF-8格式。可以参考此问题。
数据库配置如下(config.ini):
1 | [Mysql] |
页面爬虫
- 开始抓取前先观察下目标页面或网站的结构,其中比较重要的是URL的结构。链家网的二手房列表页面共有100个,URL结构为http://bj.lianjia.com/ershoufang/pg9/,其中bj表示城市,/ershoufang/是频道名称,pg9是页面码。我们要抓取的是北京的二手房频道,所以前面的部分不会变,属于固定部分,后面的页面码需要在1-100间变化,属于可变部分。将URL分为两部分,前面的固定部分赋值给url,后面的可变部分使用for循环。我们以根据小区名字搜索二手房出售情况为例:
1 | BASE_URL = u"http://bj.lianjia.com/" |
- 页面抓取完成后无法直接阅读和进行数据提取,还需要进行页面解析。我们使用BeautifulSoup对页面进行解析。
1 | soup = BeautifulSoup(source_code, 'lxml') |
- 完成页面解析后就可以对页面中的关键信息进行提取了。下面我们分别对房源各个信息进行提取。
1 | for name in nameList: # per house loop |
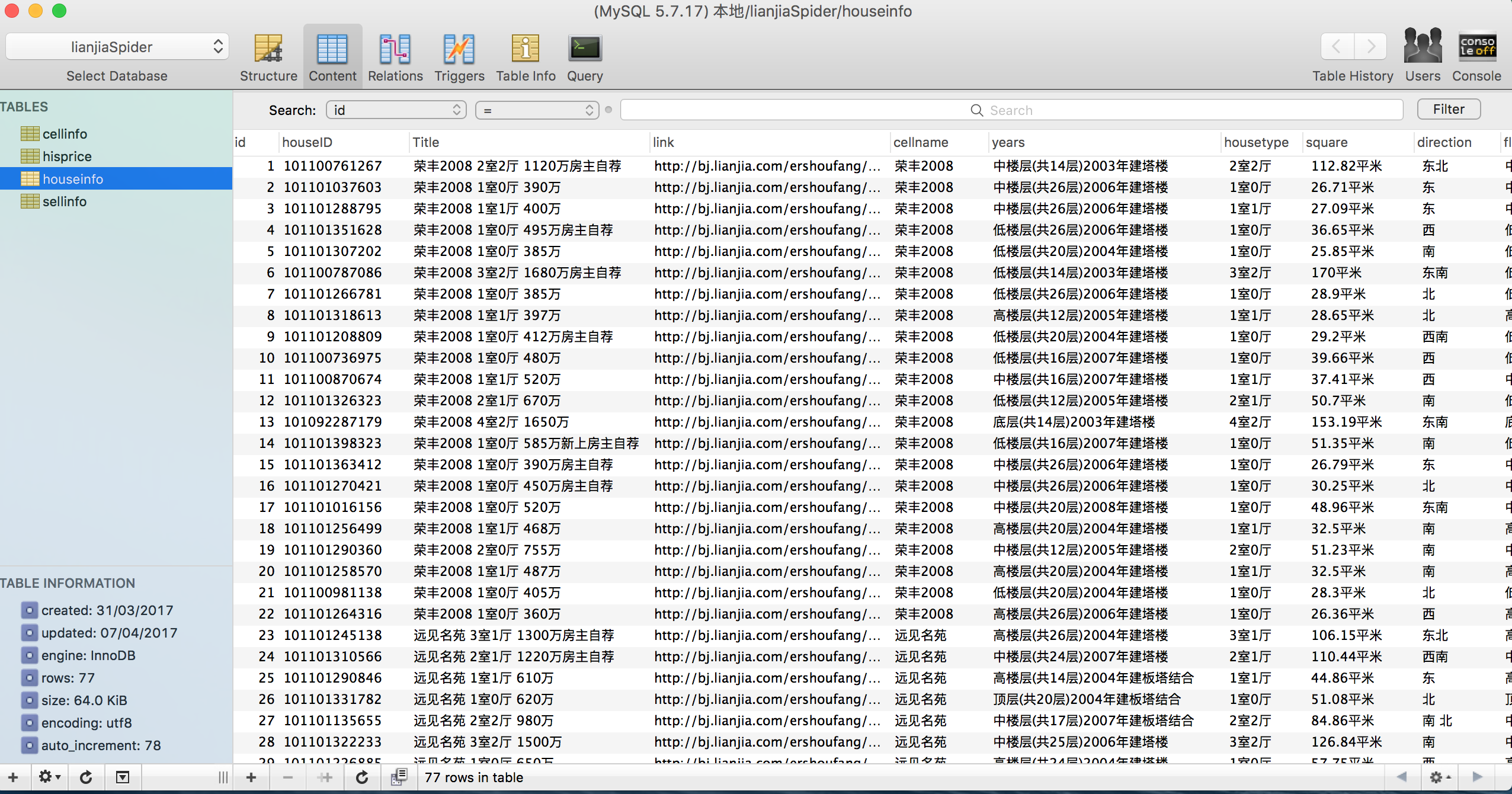
- 提取完后,为了之后数据分析,要存进之前配置的数据库中。
1 | model.Houseinfo.insert(**info_dict).upsert().execute() |
数据分析
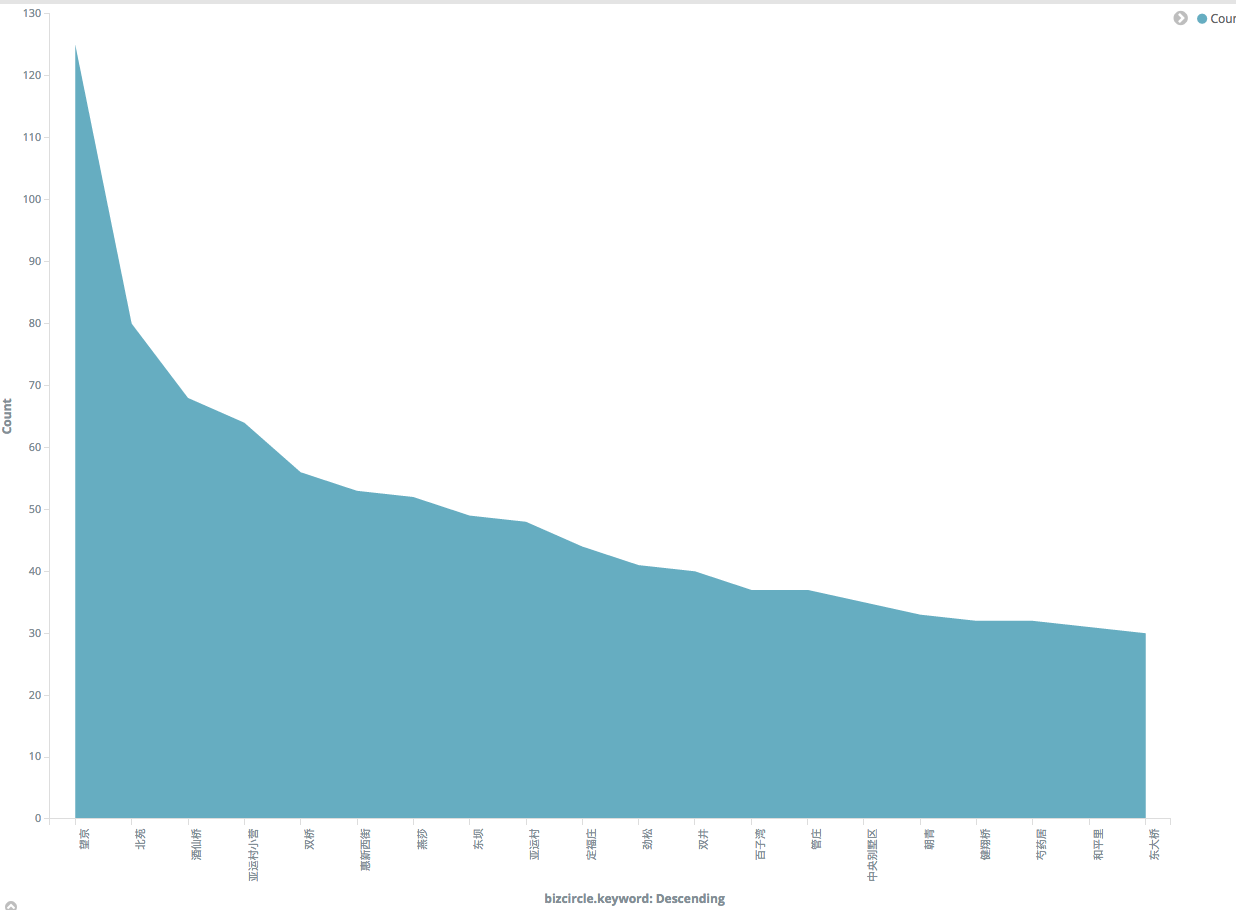
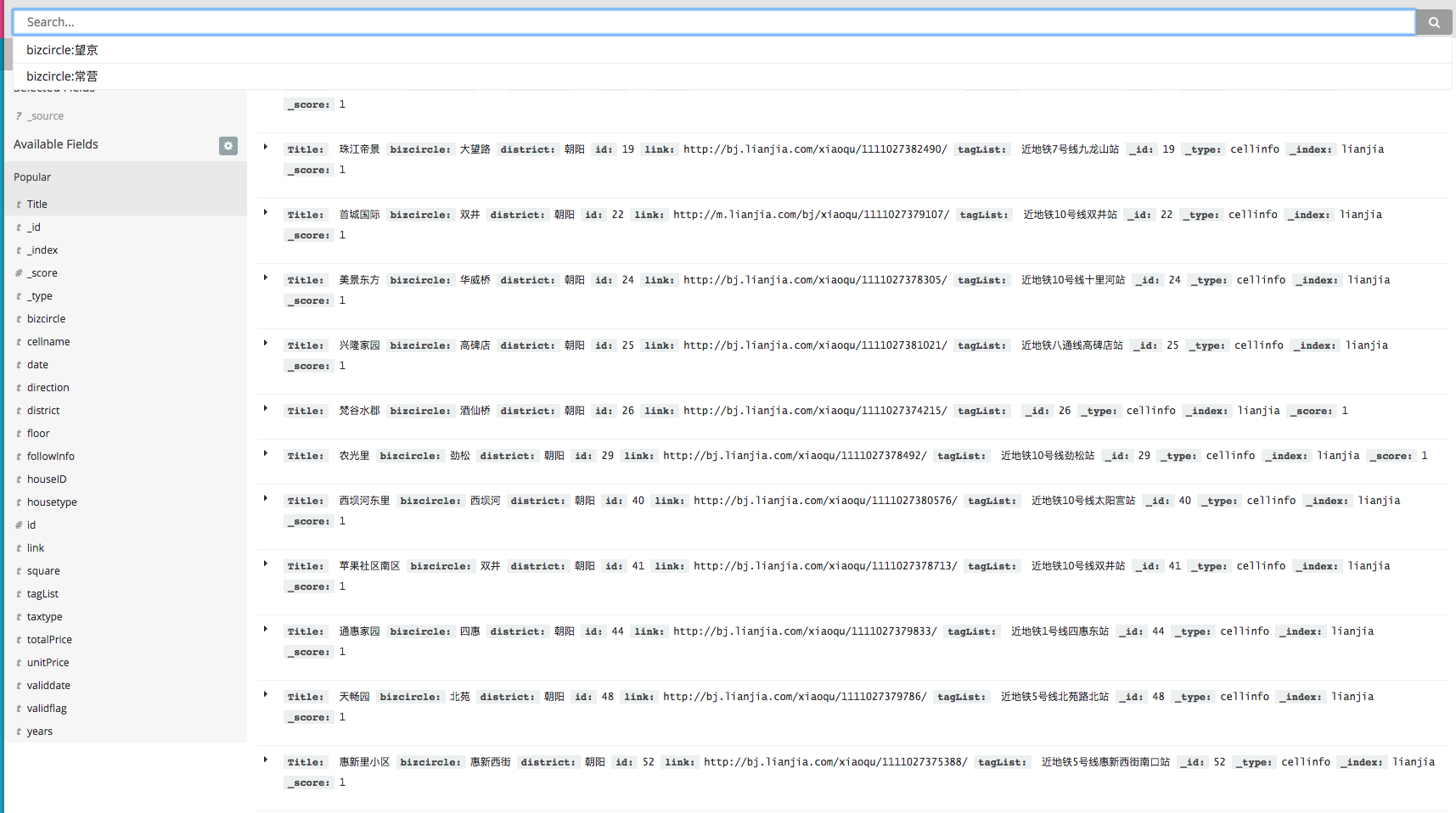
- 什么是Kibana:
Kibana是一个开源的分析与可视化平台,设计出来用于和Elasticsearch一起使用的。你可以用kibana搜索、查看、交互存放在Elasticsearch索引里的数据,使用各种不同的图表、表格、地图等kibana能够很轻易地展示高级数据分析与可视化。
Kibana让我们理解大量数据变得很容易。它简单、基于浏览器的接口使你能快速创建和分享实时展现Elasticsearch查询变化的动态仪表盘。安装Kibana非常快,你可以在几分钟之内安装和开始探索你的Elasticsearch索引数据—-—-不需要写任何代码,没有其他基础软件依赖。
Mysql数据同步到Elasticsearch:
正如上面所介绍,如果想用kibana分析数据,必须把数据导入Elasticsearch。此工具可以帮助你轻松进行mysql到es的数据同步。样例:
更多信息请参考github链家爬虫源代码。